第十二周RAG
姓名 : 阮文孟
學號 : 1111310035
實作 1
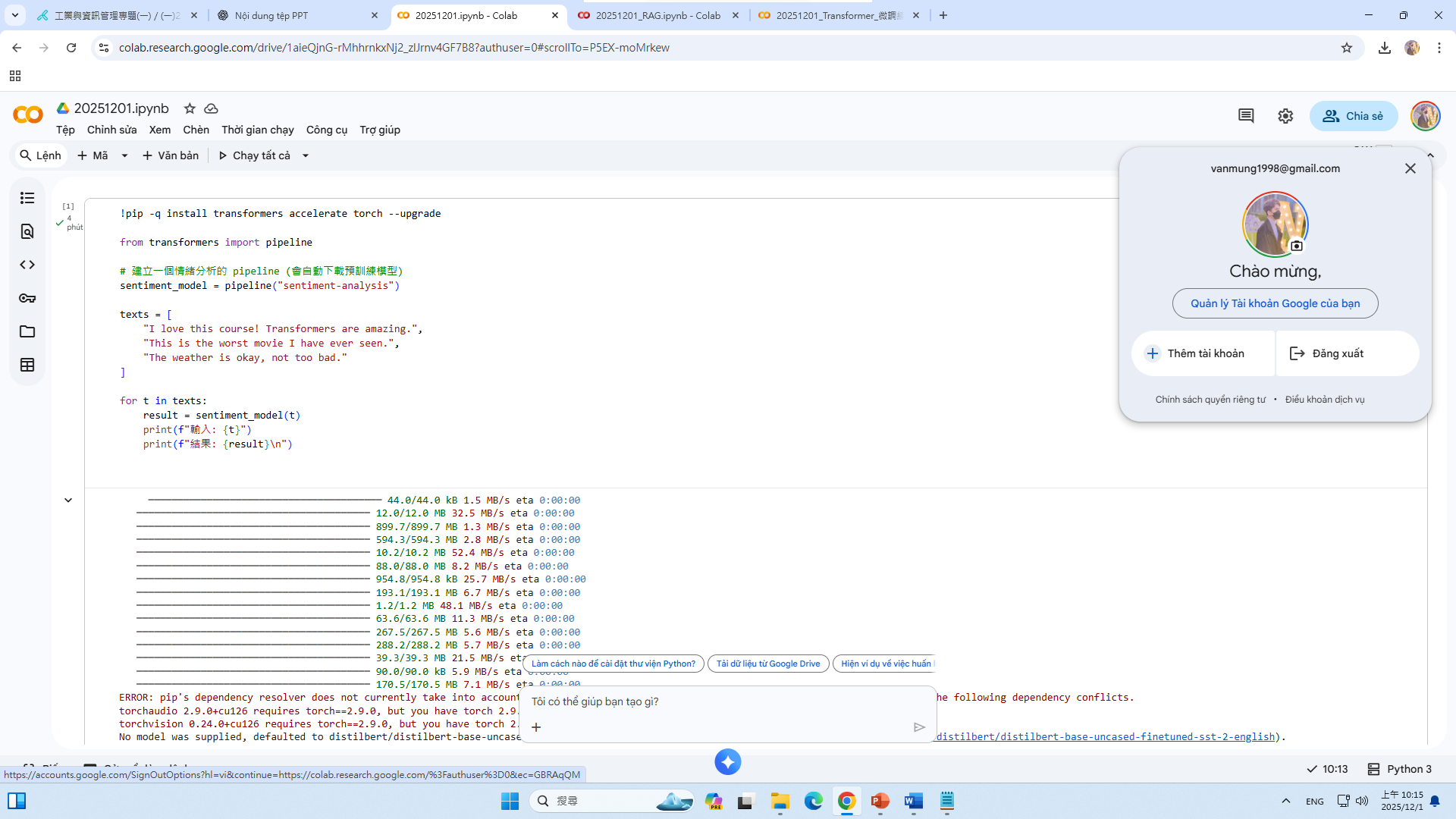
!pip -q install transformers accelerate torch --upgrade
from transformers import pipeline
# 建立一個情緒分析的 pipeline (會自動下載預訓練模型)
sentiment_model = pipeline("sentiment-analysis")
texts = [
"我喜歡旅行",
"1.2.3.4.5.6.7.8.9.10",
"The weather is okay, not too bad."
]
for t in texts:
result = sentiment_model(t)
print(f"輸入: {t}")
print(f"結果: {result}\n")
實作 2
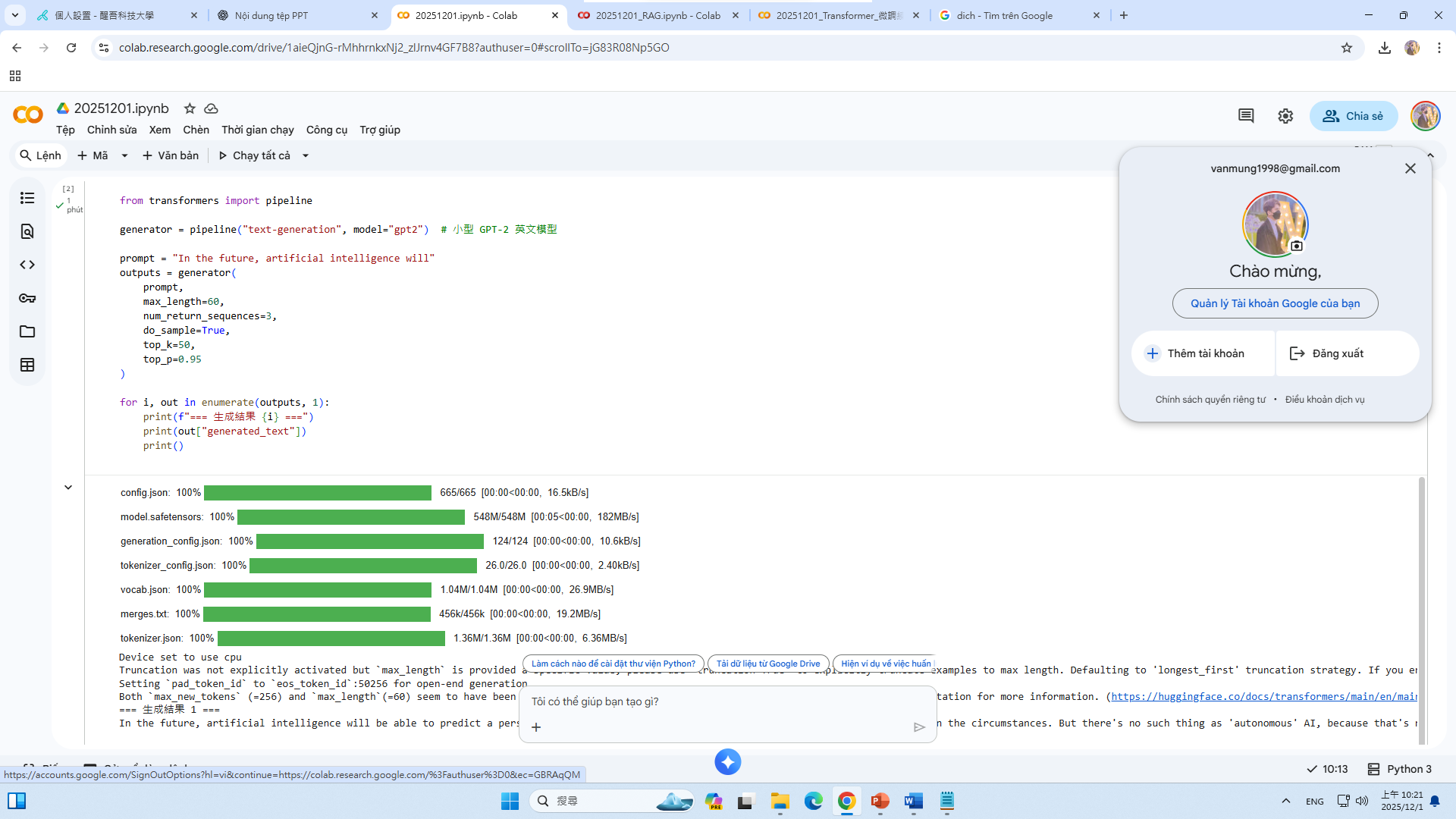
from transformers import pipeline
generator = pipeline("text-generation", model="gpt2") # 小型 GPT-2 英文模型
prompt = "In the future, artificial intelligence will"
outputs = generator(
prompt,
max_length=60,
num_return_sequences=3,
do_sample=True,
top_k=50,
top_p=0.95
)
for i, out in enumerate(outputs, 1):
print(f"=== 生成結果 {i} ===")
print(out["generated_text"])
print()
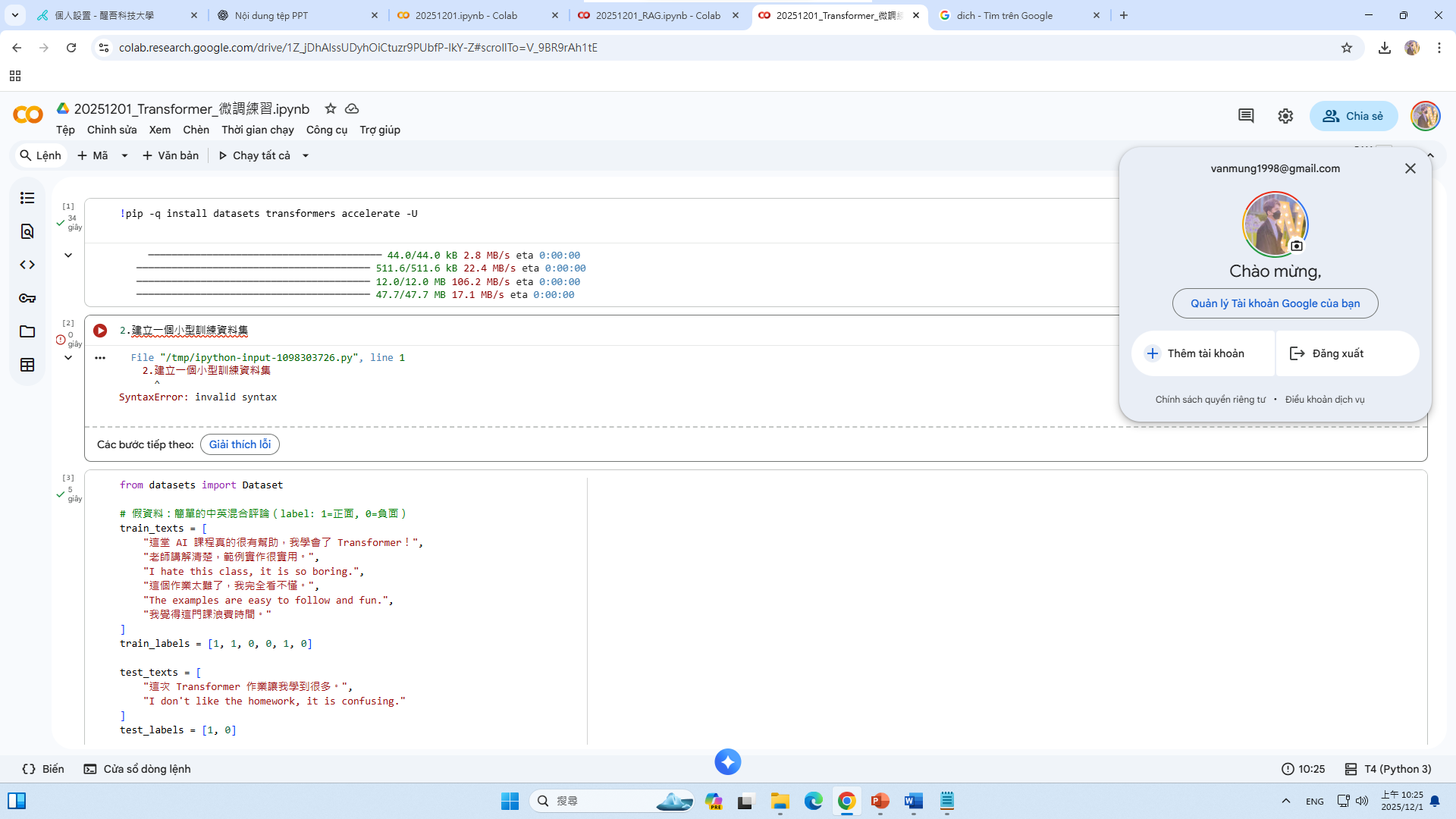
實作 3 Transformer
![]()

實作 4 ![]()
今天透過 Transformer 和 RAG 的課程,我對大型語言模型 (LLM) 的運作機制有了更深入的了解。以前我只知道 LLM 可以生成文本和回答問題,但從未想過要提供一個精確的答案,模型需要經過自我注意力 (Self-Attention) 和從外部檢索資訊的過程。透過在 Colab 上的實作,我親自操作了情感分析、文本生成,並嘗試對一個小型 BERT 模型進行微調 (Fine-tuning)。在做 RAG 的練習時,我意識到如果模型檢索到錯誤的資料,答案就會產生幻覺 (Hallucination) 且內容不相關 — 這讓我更清楚地了解資料檢索系統的設計是多麼重要。今天的課程讓我對使用現代 AI 工具更有信心,同時也看到了它們未來在學術和工作上的巨大應用潛力。我覺得這堂課非常有趣,對於我未來的方向規劃非常有幫助。